
post by nishimura at 2018.4.27 #219
 戸籍 マイナンバー 連携 戸籍制度研究会 最終取りまとめ
戸籍 マイナンバー 連携 戸籍制度研究会 最終取りまとめ
学習会「戸籍へのマイナンバー導入は何をもたらすか」記録
その1 報告 原田富弘さん
法務省戸籍制度研究会「最終取りまとめ」を読む
多数の問題を抱える「戸籍」制度と多数の問題を抱える「マイナンバー」の連携は、2019年には法案が国会に提出される予定と言われます。この方針を打ち出した法務省の「戸籍制度研究会」の報告書(最終とりまとめ)の内容を、具体的に読み解いていきます。2017年10月26日の学習会の全記録から、いらないネット原田富弘さんの報告を収録。
II 戸籍事務の現状・実態
戸籍事務の現状
戸籍事務そのものは、もともと国の事務ということなんですが、市町村長が実際の事務は執り行う、いわゆる法定受託事務として行われています。
住民基本台帳は自治事務なので、戸籍事務とはここで違いがあります。法定受託事務ということなので、地方の法務局が実際の事務にあたっての助言、指導を行っているというような関係になっています。
届出などの処理
本籍地に戸籍の正本が置かれているわけですが、いろいろな、結婚したり亡くなったりしたとき、届出そのものは本籍地以外でも可能ということになっていまして、4分の1くらいの届出が本籍地以外で届け出されているということです。そういうところに届けが出された際には、例えば結婚なんかの場合でもその人が現状でどうなっているかを確認したりするために、本籍地にどうなってますかと電話で聞いたり、公用請求をしたりすることが現状でもあります。また、本籍地以外で届出を受けた場合は、本籍地の方へと届書を送ってそこで登録をしてもらう。そんなところが現状です。
謄抄本の交付
次は戸籍の謄本・抄本などの交付ですが、これは本籍地でしか交付できないことになっていまして、窓口での請求のほか郵送請求とかいわゆるコンビニ交付――今400ほどの自治体でコンビニ交付をやっています。自治体は何の事務をやるか選べるので、戸籍のコンビニ交付をやっているのは百数十くらいの市区町村というのが現状です。
正本の保存とコンピュータ化
戸籍の正本は自治体が保存するということになっているのですが、これは平成6年の戸籍法改正で、コンピュータで処理してもいいですよ――コンピュータで処理しなさいではなくて、コンピュータで処理しても認めますよという形になっています。財政措置などがされていて、全国の自治体の99%で戸籍のコンピュータ化がされていまして、されていないところは4自治体だけということになっています。主に財政的な理由とか、メリットがないとかいった理由でやっていない。
コンピュータ化された場合、戸籍の改製が行われることになっています。そうして最新の情報をコンピュータのデータとして管理しているのですが、コンピュータ化される以前に例えば離婚したというような情報については画像として管理しているので、新しい情報しかコンピュータには載っていないのですね。
戸籍のシステム開発は、市町村ごとに独自にやっていまして、いちおう標準は国が示していますが、開発する会社ごとに例えば使われている文字の形が違うとか、データの形が違うとかいうことがあって、ネットワーク化の支障になっている。現状はネットワーク化されていません。
法務省による副本の保存
戸籍の正本に対して、副本というものを法務省が保存しています。
東日本大震災のような災害があった際に、実際4つくらいの市町村で戸籍が滅失してしまった。そうしたときに再生するための資料ということなんです。
東日本大震災のときには、その法務省が保存していた紙の資料がまた被災してしまったというようなことがあって、その後、戸籍副本データ管理システムという、コンピュータで副本を管理するシステムを法務省が作りました。全国2か所――北海道と西日本にセンターがあって、そこでデータを管理しています。
ただしそれは、バックアップ用のデータということで、利用は非常に限定されているそうです。限定された職員が必要な範囲で閲覧するということだったのですが、今回それをベースにして、戸籍の情報連携のシステムを作るということが構想されています。
戸籍についての実態調査・意識調査
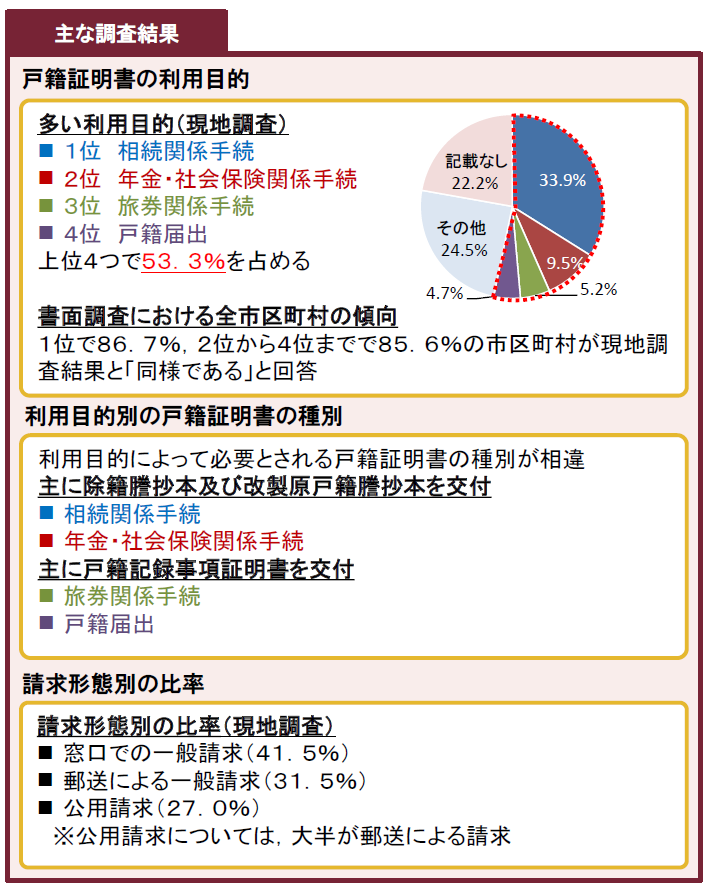
今回は、交付を受けた戸籍の利用状況についての意識調査をやっていまして、おてもとの資料集6-2の5、6ページあたりにこの調査の内容が載っています。
実態調査:戸籍を利用している行政事務と戸籍の使い方
戸籍の利用事務としては、相続、年金等の手続き、旅券、戸籍手続き――それぐらいで過半数を占めていて、それ以外が4割くらい使われているということだそうです。
 7
7
それでは実際にどういうふうに使っているかというと、2つの使い方があるそうです。
ひとつは、申請内容が正しいかどうか、本人かどうかを含めて申請内容の確認のために戸籍を確認するということ。もうひとつは、その手続きを行った人の親族的な身分関係がどうなっているのか、結婚しているのかといったことを探索するために使う。この 2 つの目的で戸籍の提出を求めるという形になっているということだそうです。
 8
8
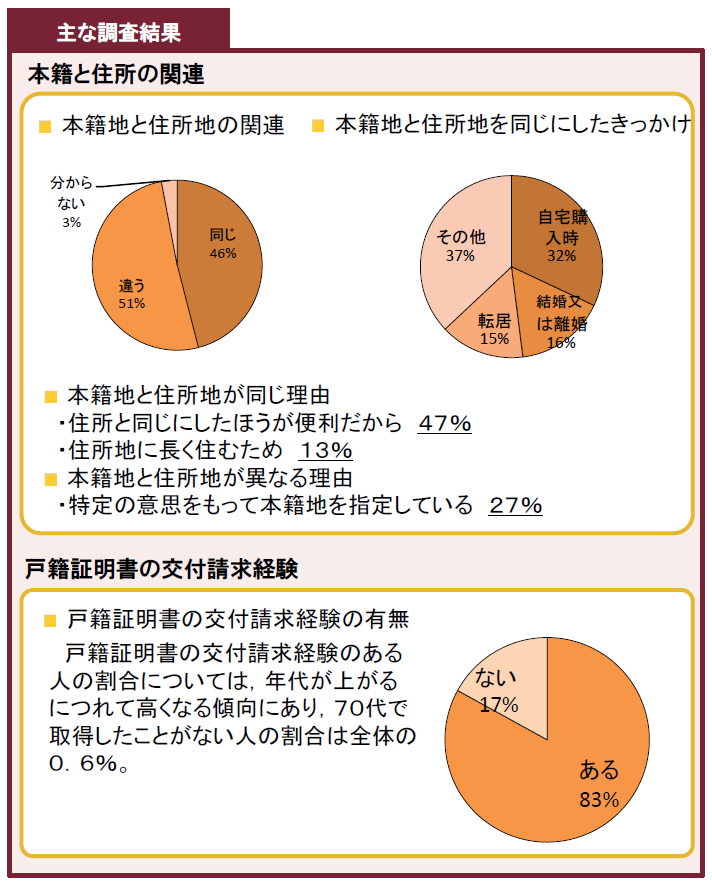
意識調査:本籍地と住民票を同じにしているか?
同時に国民の意識調査ということもやっていまして、本籍地と住民票とを同じにしている方が半分、違う方が半分くらいだそうですが、いっしょにしない理由を調査していまして、15%くらいの方は本籍地に強いこだわりがある――実家があったり故郷だというようなことで、住所地に本籍を動かしていない。
 9
9
意識調査:知られたくない情報は何か?
私たちは戸籍をプライバシー性の非常に高い、ある意味、差別的な情報ととらえているわけですが、それをオンライン化するということで、今回非常に危惧しているわけです。
意識調査の中でも、知られたくない情報は何ですか? という調査がされていまして、6 人に1人くらいの人が、知られたくない情報が入っていると答えています。その内容としては、出生とか婚姻離婚、親子関係、本籍等々――これらのことについて見られたくないとおっしゃっている方が多いということです。
戸籍について必ず問題になることのひとつは、戸籍に書かれている文字なんですね。
戸籍で標準的に使う文字はこうしなさいということは示されていますが、実際にはそれ以外の文字も使われている。なかには、申請の際にまちがった文字を書いてしまって、それがそのまま戸籍に載っているといったことを含めて、約102万字あるということです。
いちおう戸籍の統一文字として定めた5万6000字に揃えたいと国は思っているのですが、例えば戸籍の電算化を行う際にも、まちがっている字だけどこの字には愛着があるから電算化はしないでくれということで、電算化できるのにしていない戸籍――改製不適合戸籍と呼んでいますが、そういうものが電算化された自治体の中にも残っています。
こういう文字をどうするかが常に問題になってくるのですが、今回の方向性を見ても明確な解決策はなくて、どうしましょうか――みたいなことが書いてあります。
例えば「硬」という字の左側の「石」の大きさが違う。そういうことで、最終的にはお手元にある資料集10 の12ページの下の方にあるように(次図)11、できるだけ標準的な文字に整理していきたいと報告しています。
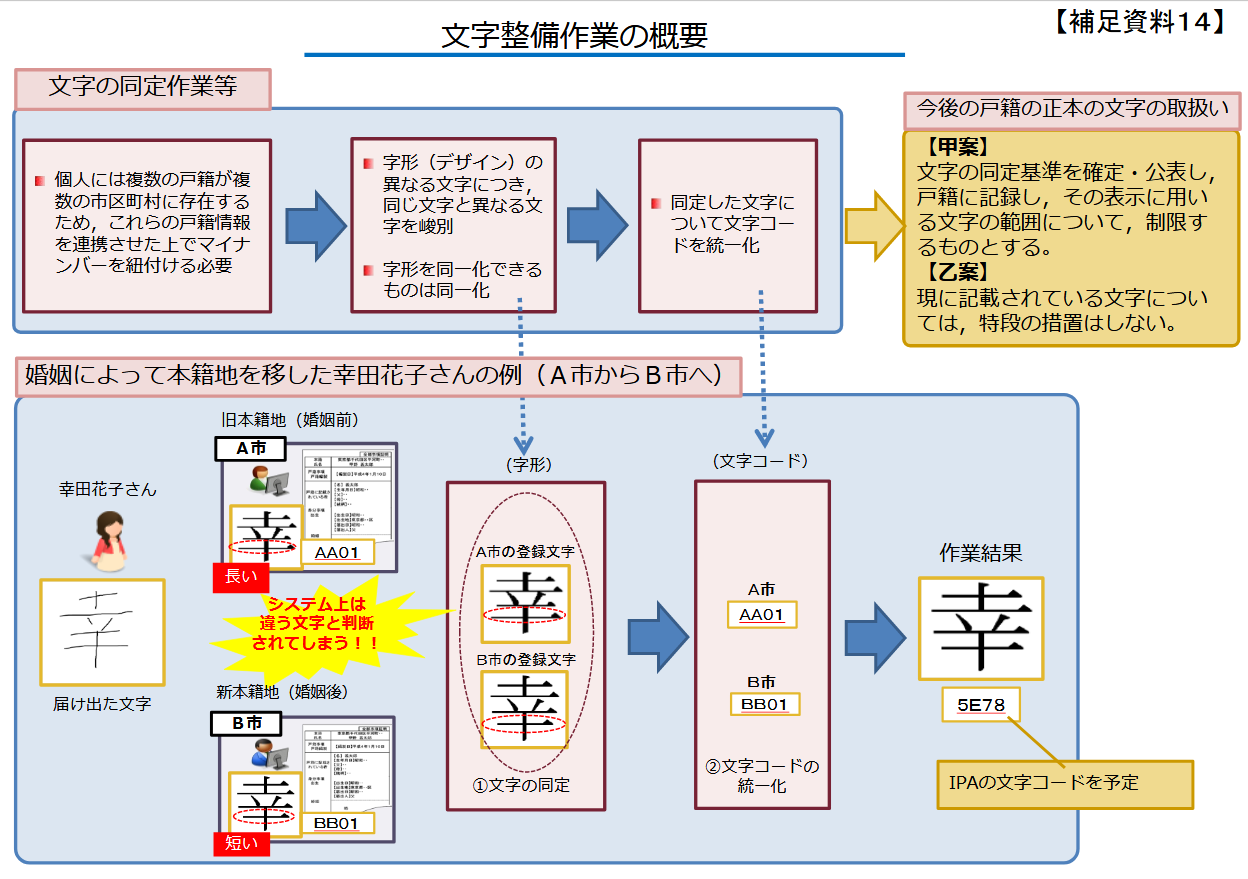
しかし、どう整理するかということについては2つの案が書いてあって、どうしたものかということになっているのが実情です。
Note
*6-2 » 原田報告資料集「マイナンバー制度の概要」(日本政府の公開資料からの抜粋)
*7 前出 » 「戸籍システム検討ワーキンググループ最終取りまとめ」 p.26収録のスライドより(部分)
*8 同前 » 「戸籍システム検討ワーキンググループ最終取りまとめ」 p.27収録のスライドより(部分)
*9 同前 » 「戸籍システム検討ワーキンググループ最終取りまとめ」 p.28収録のスライドより(部分)
*10 会場で配布した「資料集」は » こちら(zip圧縮、3.4Mバイト)からダウンロードできます。
*11 » 法務省戸籍制度に関する研究会 補足資料14「文字整備作業の概要」
◯構成・脚注:いらないネットWebエンジン(NT)/校正協力:TK


")
●2019.11.14
» 違法再委託によるマイナンバーの漏えいはどうなっているか
●2019.2.15
» 違法再委託問題で個人情報保護委員会に質問書
●2018.8.29
個人情報保護委員会ヒアリング報告
» (まとめ)個人情報保護委員会へのヒアリング報告
» (1) 住民税特別徴収額通知漏えいへの委員会の対応は?
» (2) 事業者の取得した個人番号の利用目的変更のQ&Aについて
» (3) 情報提供ネットワークシステムの監視は行われているか?
» (4) 日本年金機構の不適正な再委託にどう対応したか?
» 報告全文をPDFでダウンロード
●2018.9.14
» 個人情報保護委員会へのヒアリング報告
●2018.8.25
» 個人情報保護委員会ヒアリング&検討会
●2018.6.1
» 個人情報保護委員会に抗議声明
●2018.4.9
» 個人情報保護委員会 回答を拒否
●2018.4.9
» 個人情報保護委員会でマイナンバー制度の危険性は防げるか 2018年3月7日学習会報告
●2018.2.4
» 個人情報保護委員会へ質問書を提出しました(趣旨説明)
●2018.1.31
» 個人情報保護委員会へ質問書を提出しました
●2017.4.24
» 2017.3.3 省庁等交渉レポート最終回 個人情報保護委員会は機能しているか





